Programs which use stacks can often be rewritten to simply use recursion (since recursion deals with an implicit stack. Hence the maze-running program can be rewritten as follows, where caller is responsible for setting success to false and current to start originally:
public void runMaze()
{
Position origCurrent = current; // Save orig value
current.visit();
success = current.equals(finish); // Are we finished?
while (current != null && !success)
{ // Search until success or run out of cells
current = nextUnvisited(); // Find new cell to visit
if (current != null)
{
current.visit();
runMaze(); // Try solving maze from new current
current = origCurrent; // reset to try again
}
}
}
public interface Queue extends Linear {
public void enqueue(Object value);
// post: the value is added to the tail of the structure
public Object dequeue();
// pre: the queue is not empty
// post: the head of the queue is removed and returned
public void add(Object value);
// post: the value is added to the tail of the structure
public Object remove();
// pre: the queue is not empty
// post: the head of the queue is removed and returned
public Object peek();
// pre: the queue is not empty
// post: the element at the head of the queue is returned
public int size();
// post: returns the number of elements in the queue.
public void clear();
// post: removes all elements from the queue.
public boolean isEmpty();
// post: returns true iff the queue is empty
}
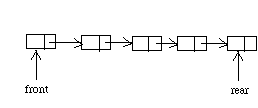
Which way should pointers go? From front to rear or vice-versa?
If the
pointers point from the rear to the front, it will be quite difficult to remove
the front element. As a result, we orient them to point from the front to the
rear.
All of the operations are O(1).
The text and structures package implementation originally used a singly-linked list. This was a bad decision since it makes add an O(n) operation.
The doubly-linked list is an alternative mentioned in the text, but that involves wasted space. Another alternative would have been a circular list. The best alternative would have been a singly-linked list with references to both the front and rear.
The main problem with this is that deletions and additions to the queue will result in elements removed from the left side and added to the right side. Thus the queue will "walk" off to the right over time, even if it remains the same size (e.g., imagine what happens after 100 adds and 100 removes). While the vector will keep growing to compensate, the Vector will keep growing and each time it grows, it will cost twice as much.
Alternatively we could change the deletions so that the element at the head (0 index) is actually removed. However this would make the remove method O(n).
Suppose we can set an upper bound on the maximum size of the queue.
How can we solve the problem of the queue "walking" off one end of the array?
Instead we try a 'Circular' Array Implementation w/ "references" (subscripts) referring to the head and tail of the list.
We increase the subscripts by one when we add or remove an element from the queue. In particular, add 1 to front when you remove an element and add 1 to rear when you add an element. If nothing else is done, you soon bump up against the end of the array, even if there is lots of space at the beginning (which used to hold elements which have now been removed from the queue).
To avoid this, we become more clever. When you walk off one end of the array, we go back to beginning. Use
index = (index + 1) mod MaxQueue
to
walk forward. This avoids the problem with falling off of the end of the
array.
Exercise: Before reading futher, see if you can figure out the representation of a full queue and empty queue and how you can tell them apart.
Notice that the representation of a full queue and an empty queue can have identical values for front and rear.
The only way we can keep track of whether it is full or empty is to keep track of the number of elements in the queue. (But notice we now don't have to keep track of the rear of the queue, since it is count-1 after front.)
There is an alternative way of keeping track of the front and rear which allow you to determine whether it is full or empty without keeping track of the number of elements in the queue. Always keep the rear pointer pointing to the slot where the next element added will be put. Thus an empty queue will have front = rear. We will say that a queue is full if front = rear + 1 (mod queue_length). When this is true, there will still be one empty slot in the queue, but we will sacrifice this empty slot in order to be able to determine whether the queue is empty or full.
public class QueueArray implements Queue
{
protected Object data[]; // array of the data
protected int head; // next dequeue-able value
protected int count; // # elts in queue
public QueueArray(int size)
// post: create a queue capable of holding at most size
// values.
{
data = new Object[size];
head = 0;
count = 0;
}
public void enqueue(Object value)
// post: the value is added to the tail of the structure
{
Assert.pre(!isFull(),"Queue is not full.");
int tail = (head + count) % data.length;
data[tail] = value;
count++;
}
public Object dequeue()
// pre: the queue is not empty
// post: the element at the head of the queue is removed
// and returned
{
Assert.pre(!isEmpty(),"The queue is not empty.");
Object value = data[head];
head = (head + 1) % data.length;
count--;
return value;
}
public Object peek()
// pre: the queue is not empty
// post: the element at the head of the queue is returned
{
Assert.pre(!isEmpty(),"The queue is not empty.");
return data[head];
}
...
public int size()
// post: returns the number of elements in the queue.
{
return count;
}
public void clear()
// post: removes all elements from the queue.
{
// we could remove all the elements from the queue.
count = 0;
head = 0;
}
public boolean isFull()
// post: returns true if the queue is at the capacity.
{
return count == data.length;
}
public boolean isEmpty()
// post: returns true iff the queue is empty
{
return count == 0;
}
}
The complexity of operations for the array implementation of the queue is the same as for the linked list implementation.
There are the same trade-offs between the two implementations in terms of space and time as with stacks above. Notice that we do not bother to set array entry for dequeued element to null. Similarly with clear. Thus the garbage collector would not be able to sweep up removed elements even if not in use elsewhere. It would probably make sense to be more consistent with Vector and clean up behind ourselves.