|
|
CSCI 256
|
Only turn in problems from the second section.
Illustrate how to use Ford-Fulkerson to find a maximal matching in the following bipartite graph:
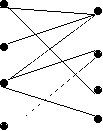
Solution: Add new source and sink nodes and add edges from the source to left nodes and from right nodes to sink. Make all edges have capacity 1, and solve using Ford-Fulkerson. I.e., compute residual network, look for path from source to sink, add corresponding flow to the original and repeat until residual network has no path from source to sink.
If nodes on left are labelled A, B, C, D (from top to bottom) and those on right are labelled E, F, G, H, then solution will have flow of 1 on edges AG, BE, CH, and DF (as well as all edges from source and entering sink). The matching will then include the same four edges.
Design an O(V+E) algorithm for finding a maximum matching in a tree. Hint: Think recursively and start with a leaf. Be sure to prove that you have a maximum matching and that it is linear time.
Solution: The following algorithm actually works on a forest (collection of disjoint trees). Make a pass through the forest, F, and add all leaves to a queue, Q. If there is only one node in the tree then the empty matching is the only one possible. If there are two or more nodes, remove a leaf u from Q. Let e be the edge between u and its parent, p. Remove u, p, and all edges (including e) incident on the parent. If any new leaves are formed in the resulting tree, add them to Q. Recursively call the algorithm on the resulting forest F' and add e to the set M returned by the recursive call.
We first show M is maximal. We do this by induction on the number of nodes in the graph. If F has only one node then the empty matching is the only one possible. Suppose the resulting M is maximal for all trees with less than n vertices. Let F be a forest with n vertices. Following the algorithm choose leaf u with parent p and let e be the edge between them. Let M' be a maximal matching of F. Suppose e is not in M'. Therefore u is not matched by M' (e is the only edge incident on u because it is a leaf). Because M' is maximal, there must be an edge e' of M' which contains p (otherwise we could add e to M' getting a larger matching). Remove e' from M' and replace it with e giving M''. This is also a matching and it has the same size as M', so it must also be maximal. Notice that M' - {e'} is a matching of the forest F' obtained by removing u, p, and all edges incident on p. Because a recursive call of the algorithm on F' results in a maximal matching, its cardinality is at least as great as that of M'-{e'}. Thus the final matching returned by the algorithm has cardinality at least as great as M', and hence is maximal.
The complexity of the algorithm is O(V+E): The initial pass finding leaves is O(V+E). Each vertex is added to and removed from the Q once. Each edge is erased from the graph exactly once. Therefore the total time is O(V+E)
Let G be an undirected bipartite graph, and let M be an arbitrary matching in G. Construct an algorithm to find a maximum matching in G that covers all the vertices that M covers. (A vertex is covered by a matching M if it is incident to one of the edges of M.) Note that edges in M may be dropped in finding the maximal matching, you are only asked to show that vertices that were mentioned in the original M are also mentioned in the final matching. Hint: Look at how we found maximum matchings and examine the algorithm carefully. You may need to make minor modifications or restrictions to preserve vertices.
Solution: Build the flow network corresponding to G and add a flow which corresponds to M. That is put flow 1 on all edges from L to R that are in M, and add a flow of 1 from the source to all vertices in L involved in M and a flow of 1 from all vertices of R in M to t. Now use Ford-Fulkerson to construct a maximal flow starting with f. Take the resulting maximal flow f' to get a new M' = {(u,v) | f'(u,v) = 1}.
Now e in M does NOT imply e in M' because some flows may have been reduced using residual networks. However, if when we perform Ford-Fulkerson we make sure there are no cycles in the augmenting paths in the residual network then all nodes involved in M will still be involved in M'.
Because there are no cycles, an augmenting path will never go from a node in L back to the source node s (if it did, there would be a cycle since the augmenting path always starts at s). Suppose the augmenting path goes backwards from R to L by going from node vi in R to uj in L, and from there to node vk in R again (because we never go back to s). Suppose also that the node before vi in the augmenting path is ul in L. (Again it couldn't have come from t because the augmenting path ends in t and there are no cycles.) Then when the flow is updated, the flow (with value 1 since the capacity is 1) from uj to vi will be erased, while new flows will be added from ul to vi and from uj to vk. Thus even though the edge from uj to vi is erased, there is still flow from uj (namely to vk) and to vi (from ul). Therefore at each step of the algorithm, if an edge in M is erased (by setting its flow to 0), new edges are added to M (by setting their flows to 1) that include the endpoints of the edge that were erased. As a result the final matching contains all of the vertices of the matching we started with, even though many of the original edges may no longer appear!
Problem 27-3 on page 627.
Hints:For part a, interpret the solution to part a as telling you that given a cut (S,T), if the node corresponding to an experiment is in T, then so are all of the nodes corresponding to the instruments needed to perform that experiment.
For part b, note that minimizing the value V of a cut is equivalent to maximizing the value of P - V for any T. Use this with P = sum of all of the pj to get an expression involving the net revenue for running the experiments in T (where (S,T) is the minimum cut).
You need not analyze the complexity of your algorithm, but do write out carefully the algorithm.
Solution:
Let (S,T) be a cut with finite-capacity. Suppose Ik in Rj. Thus there is an edge with infinite capacity running from Ik to Ej. If Ej is in T then Ik must also be in T since otherwise the edge crosses the cut and the cut would have infinite capacity.
The interpretation of this is that if Ej is in T, then all of the instruments needed to perform Ej are also in T.
Let (S,T) be a finite capacity cut of G. The capacity of the cut is the sum of the pi such that Ei is in S (recall t does not occur in S, so the edge from Ei to t must cross the cut) plus the sum of the cj such that Ij is in T (again, each of these corresponds to an edge from s to Ij crossing the cut).
Thus the minimum cut will have capacity
SumEi in S pi + SumIj in T cjOf course minimizing this is equivalent to maximizing
T - (SumEi in S pi + SumIj in T cj)for T an arbitrary number. Pick T = Sumi=1,...,m pi. Then
T - (SumEi in S pi) = SumEi in T pi
Thus the minimum cut corresponds to maximizing
SumEi in T pi - SumIj in T cj
The above expression also corresponds to the net revenue obtained by choosing the experiments Ei in T. (Recall from part a that if Ei is in T, then so are all of the instruments needed to perform the experiment.) Thus finding the min cut determines the choice of experiments resulting in the maximum net revenue.
Solve the maximum flow problem for the graph constructed as usual and then use the proof of Theorem 27.7 (2 => 3) to find the minimum cut (S,T) and let T determine which experiments should be taken on the space shuttle.
In more detail: Find the maximum flow using Ford-Fulkerson. Build the residual network Gf. Then use depth-first or breadth-first search to find the set S of all the nodes accessible from s. The set of experiments to take is all of the Ei such that Ei is not in S.
Let S1, ..., Sk be a collection of sets. A system of distinct representatives (SDR) is a set R = {r1, ..., rk} of distinct elements such that ri in Si, for all 1 <= i <= k. In other words, R includes exactly one representative from each set. It is not always possible to find an SDR of a given collection of sets. For example, there is no SDR for the collection of sets S1 = {1,2}, S2 = {2,3,4}, S3 = {1,3}, S4 = {1,2,3}, and S5 = {2,3}. However, if we leave off S5, the first four sets have SDR {1,4,3,2}.
Design an algorithm that, given a collection of sets, determines whether that collection has a SDR, and, if so, returns the SDR. Hint: Reduce this to the problem of finding a maximal matching of a bipartite graph G where L is a set of vertices with one vertex, ui, corresponding to each Si and R is a set of vertices with one vertex, vj, corresponding to each element ej in the union of the Si's.
Be sure to discuss the translation of input to appropriate input for the matching as well as the translation of the output to the appropriate answer for the SDR problem. What is the complexity of the algorithm?
Solution: Set up the graph with vertices as suggested and with edge from ui to vj iff element ej is an element of set Si. This is now a bipartite graph. Find a maximal matching. If every ui is involved in the match, then there is an SDR, and the set can be found by looking at the vj's matched with the ui.
The complexity is found by adding the time to set up the graph to the time it takes to solve the matching. Suppose there are k sets and a total of m elements in the union of the sets. if k > m then there is no possibility of finding a SDR, so we assume k <= m. There are k+m nodes in the graph and a maximum of k*m edges in the graph, so it takes time O(k+m+k*m) = O(k*m) to set up the graph. The matching takes time O(VE) = O((k+m)*k*m) = O(k*m2) to solve the matching. Therefore the total complexity is O(k*m2).
Back to:
kim@cs.williams.edu